What We Need to Know About AI: A Snapshot for All Critical Care Anesthesiologists
The integration of Artificial Intelligence (AI) in various industries has progressed rapidly in medicine, particularly in critical care. The number of articles published regarding AI in critical care medicine tripled from 2018 to 2020.1 From the use of AI to predict the likelihood of sepsis, intensive care unit (ICU) mortality, and length of stay, many predictive models have been developed for use in the ICU setting. It is essential for the modern intensivist to understand the basics of how AI works and how to analyze studies based on AI. This article aims to fulfill these two goals and provide a foundation of knowledge that can be used to implement AI in your practice.
The first step is to understand what AI is as well as the terminology surrounding the topic. AI in its most basic form works through machine learning. Machine learning (ML) is when an algorithm can make predictions, which aren’t explicitly coded, based on a data set they are exposed to. There are two major subtypes of machine learning: supervised and unsupervised learning. Supervised learning involves inputting data with a certain label and allowing the algorithm to learn the link between the two. For example, AI has been used to predict the likelihood of sepsis in the ICU. The algorithm was exposed to multiple data points including vitals and labs for patients that developed sepsis while in the ICU. It was able to successfully link the relationship between the data and the label (patients who developed sepsis) to accurately predict which patients would develop sepsis 4-12 hours before onset.2 Unsupervised learning involves inputting data without the use of labels and allowing the algorithm to discover patterns or groupings within the data.3
When evaluating studies involving AI there are a few key things to look for to assess the quality of the study. One of the most important factors is the quality and quantity of data the algorithm was exposed to.4 When developing the ML model, the algorithm should be exposed to a training set, test set, and validation set. The training set is the initial data that the model is exposed to and learns from. The labels assigned to the data must be truly accurate, so it is important to note how they were created. Were labels automatically generated based on a diagnosis in an EMR or using expert opinion or using a pathological diagnosis? After this initial learning process, the model is exposed to a test set which allows the programmer to adjust certain parameters to increase the accuracy of the model. The test set is vital as it prevents the ML model from completely memorizing the training data. This is known as “overfitting” when an ML model only works well on data it was trained on and not on new data.5 Finally, the algorithm should be exposed to a completely new dataset for external validation.
In an article by Fleuren et al, which looked at 172 articles regarding AI in critical care medicine, only 5% of studies had a validation set that was different from the training and tuning set.6 Ideally, all three data sets should have no overlap to yield the best possible study. During this validation process, the reference standard must be of high quality and blinded as this can drastically affect the results. For example, in developing AI that could detect diabetic retinopathy based on fundoscopic images an ML model was validated against a panel of retinal specialists. Krause et al showed that when using a majority vote of 3 retinal specialists as the reference standard the ML model had an error of 6.6% but when using a reference standard with adjudicated grades from 3 specialists, the error by the same ML model was 4.6%. This shows the impact that a higher quality and more stringent reference standard has on the ability to estimate the model's performance.7 It is important to keep in mind that certain things in critical care medicine have a subjective aspect which can make it difficult to set up a reasonable reference standard. For example, in a study conducted by Sjoding et al. which looked at interobserver reliability for the diagnosis of ARDS using the Berlin definition it was found to have a kappa of 0.5. A kappa of 1 being perfect agreement between observers and 0 being no agreement.8
The most common way to report the performance of AI models is by presenting a receiver operating characteristic (ROC) curve and reporting the area underneath the curve (AUC) (Figure 1). The ROC curve plots the true-positive rate against the false-positive rate and the area underneath it summarizes the test's overall performance. An AUC of 1 is a perfect model that has 100% sensitivity and specificity. It is important for the model to not only have a high AUC but also affect clinical outcomes. It is important to look at all the data and not just the AUC to come to an accurate conclusion regarding the model. There are numerous other metrics that can be used to evaluate performance including F1 score, precision, and recall, which the intensivist should familiarize themselves with. This is discussed by the transparent reporting of a multi-variable prediction model for individual prognosis or diagnosis (TRIPOD) guidelines.9
With increasing research and development in the field of AI applications in healthcare and growing application in critical care ranging from sepsis prediction models to automated ejection fraction estimation, critical care anesthesiologists need to familiarize themselves with the basic understanding of AI. This understanding equips them with knowledge to not only review the literature, evaluate AI enabled devices in clinical workspace but also contribute to the growing field of AI in perioperative medicine.
Disclosure Statement:
This article received no specific grant from any funding agency in the public, commercial, or not-for-profit sector.
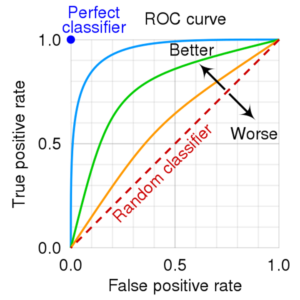
Figure 1. Receiver operator characteristic curve that demonstrates that an area under the curve more closely approaching a true positive rate of 1 is more sensitive and specific and therefore “better” than an area under the curve that approaches a true positive rate of 0 which would be less sensitive and specific, “worse.”
ROC Curve. cmglee (2021, September 9). CC BY-SA 4.0
References:
- Cui X, Chang Y, Yang C, Cong Z, Wang B, Leng Y. Development, and trends in Artificial Intelligence in Critical Care Medicine: A bibliometric analysis of related research over the period of 2010–2021. Journal of Personalized Medicine. 2022;13(1):50. doi:10.3390/jpm13010050
- Nemati S, Holder A, Razmi F, Stanley MD, Clifford GD, Buchman TG. An Interpretable Machine Learning Model for Accurate Prediction of Sepsis in the ICU. Crit Care Med. 2018;46(4):547-553. Doi:10.1097/CCM.0000000000002936
- Dike HU, Zhou Y, Deveerasetty KK, Wu Q. Unsupervised learning based on Artificial Neural Network: A Review. 2018 IEEE International Conference on Cyborg and Bionic Systems (CBS). Published online 2018. doi:10.1109/cbs.2018.8612259
- Meskó B, Görög M. A short guide for medical professionals in the era of Artificial Intelligence. npj Digital Medicine. 2020;3(1). doi:10.1038/s41746-020-00333-z
- Faes L, Liu X, Wagner SK, et al. A clinician’s Guide to Artificial Intelligence: How to critically appraise machine learning studies. Translational Vision Science & Technology. 2020;9(2):7. doi:10.1167/tvst.9.2.7
- Fleuren LM, Thoral P, Shillan D, Ercole A, Elbers PWG; Right Data Right Now Collaborators. Machine learning in intensive care medicine: ready for take-off? Intensive Care Med.2020;46(7)1486-1488. Doi:10.1007/s00134-020-06045-y
- Krause J, Gulshan V, Rahimy E, et al. Grader variability and the importance of reference standards for evaluating machine learning models for diabetic retinopathy. Ophthalmology. 2018;125(8):1264-1272. doi: 10.1016/j.ophtha.2018.01.034
- Sjoding MW, Hofer TP, Co I, Courey A, Cooke CR, Iwashyna TJ. Interobserver Reliability of the Berlin ARDS Definition and Strategies to Improve the Reliability of ARDS Diagnosis. Chest. 2018;153(2):361-367. Doi: 10.1016/j.chest.2017.11.037
- Burke HB. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (tripod). Annals of Internal Medicine. 2015;162(10):735. doi:10.7326/l15-5093
Authors



Categories
- Announcements
- Annual Meeting
- Award
- Book & Media Reviews
- Call for Articles
- Case Reports
- Clinical Research Consortium
- Committee Reports
- Council Report
- COVID-19
- DEI
- Early Career Intensivists
- Editor’s Message
- Featured Articles
- Fellows
- Jobs
- Literature Survey
- Match Applicants
- Medical Ethics
- Member Essays
- Member Spotlight
- Opinion
- Patient Safety Series
- PDAC
- President’s Corner
- Private Practice
- Pro/Con
- Research Updates
- Social Media Highlights
- Submission Guidelines
- Topical Review
- Wellness Series
- White Papers
- Women in Critical Care
- Work-Life Balance
Current Newsletter

Past Newsletters
Drip
















ASA 2023 Annual Meeting







September is Women in Medicine Month and throughout the month, four of our members will be sharing their experiences as a woman in critical care.




IARS & SOCCA Abstracts 2023
Abstracts of International Anesthesia Research Society & Society of Critical Care Anesthesiologists 2023 Annual Meetings are available in the May 2023 issue of Anesthesia & Analgesia.

Podcasts
SOCCA Women in Critical Care has collaborated with Stanford Continuing Medical Education for a Stanford Medcast Women in Critical Care podcast mini-series.
Episode #66—”Psychosocial Challenges Facing Physicians”—stream now
SOCCA polled the WICC and got the answers we wanted to hear about. We hope this episode helps at least one person out there!
If you have 21 minutes, listen and get your CME credit!

Episode #65—”Stereotype Threats”—stream now

Episode #63: “The Wicked Problem of Physician Well-Being”—stream now

Episode #59—“Underestimation of Influence”—stream now



